Tool-Lab
Evaluating LLM Tool Use as Resource-Rational Planning
LLM agents should be evaluated not only by whether they get the answer right, but by whether they acquire information efficiently under resource constraints.
A hidden table, observable tool calls, cumulative cost, and a final decision.
Final answers are not enough
Most LLM benchmarks score final outputs, but agentic models also choose what information to gather, what tools to call, how long to reason, and when to stop.
Efficiency is becoming a new metric
Model benchmarks increasingly emphasize doing the same task with fewer tokens or lower cost. Tool-Lab asks whether the planning process itself is efficient.
The evaluation target is shifting from raw capability to capability per unit cost.
When LLMs look biased
Alongside efficiency, there is another open puzzle: LLMs display human-like cognitive biases.
"...the clichés and biases exhibited by LLMs, emphasizing that the presence of these biases is not due to the models’ mental capacities but due to the data they are trained on."
— Macmillan-Scott & Musolesi (2024). (Ir)rationality and cognitive biases in large language models.
Artifact of training data, or adaptive shortcut under constraints?
From Pure to Resource Rationality
How our understanding of human cognition has evolved to account for computational and informational limits.
Pure Rationality
Expected Utility Theory (von Neumann & Morgenstern). Assumes agents have infinite cognitive resources to find the objectively optimal choice.
Bounded Rationality
Herbert Simon introduces limits to cognition. Instead of maximizing, humans use heuristics and “satisfice” (accepting a good-enough solution).
Resource Rationality
Lieder & Griffiths formalize cognition as an optimization problem: maximizing expected utility net of computational and time costs.
Bias can be a cost-saving policy
Resource rationality says agents should maximize expected utility net of computation, information, time, and monetary costs.
- Classical rationality: exhaustively search for the perfect answer.
- Bounded rationality: use heuristics because compute is limited.
- Resource rationality: stop when another API call isn't worth the token cost.
Tool-Lab makes search observable
Task-relevant information is hidden behind explicit tool calls, so the model's information-acquisition process becomes measurable.
inspect_cell(option_id, attribute_id)
submit_choice(option_id)
Cumulative tool cost: 0
The unit of analysis is the trajectory
Two models can choose the same final answer but follow very different policies.
A sequential decision problem
Tool-Lab can be formalized as a Markov decision process, making LLM tool use comparable to optimal planning policies. Once the task is an MDP, the observed LLM trajectory can be compared against exhaustive search, heuristic search, and the optimal cost-aware policy.
| Policy | Tool Cost | Accuracy |
|---|---|---|
| Exhaustive | High | High |
| Heuristic | Low | Variable |
| Optimal | Moderate | High enough |
Why product choice?
Consumption tasks give us hidden attributes, known utility functions, interpretable heuristics, and controllable information costs.
Because true best options are computable, we can score both final choice and search behavior. The empirical studies use two marketing biases to test whether final-output biases are mediated by information-search policies.
Study Roadmap
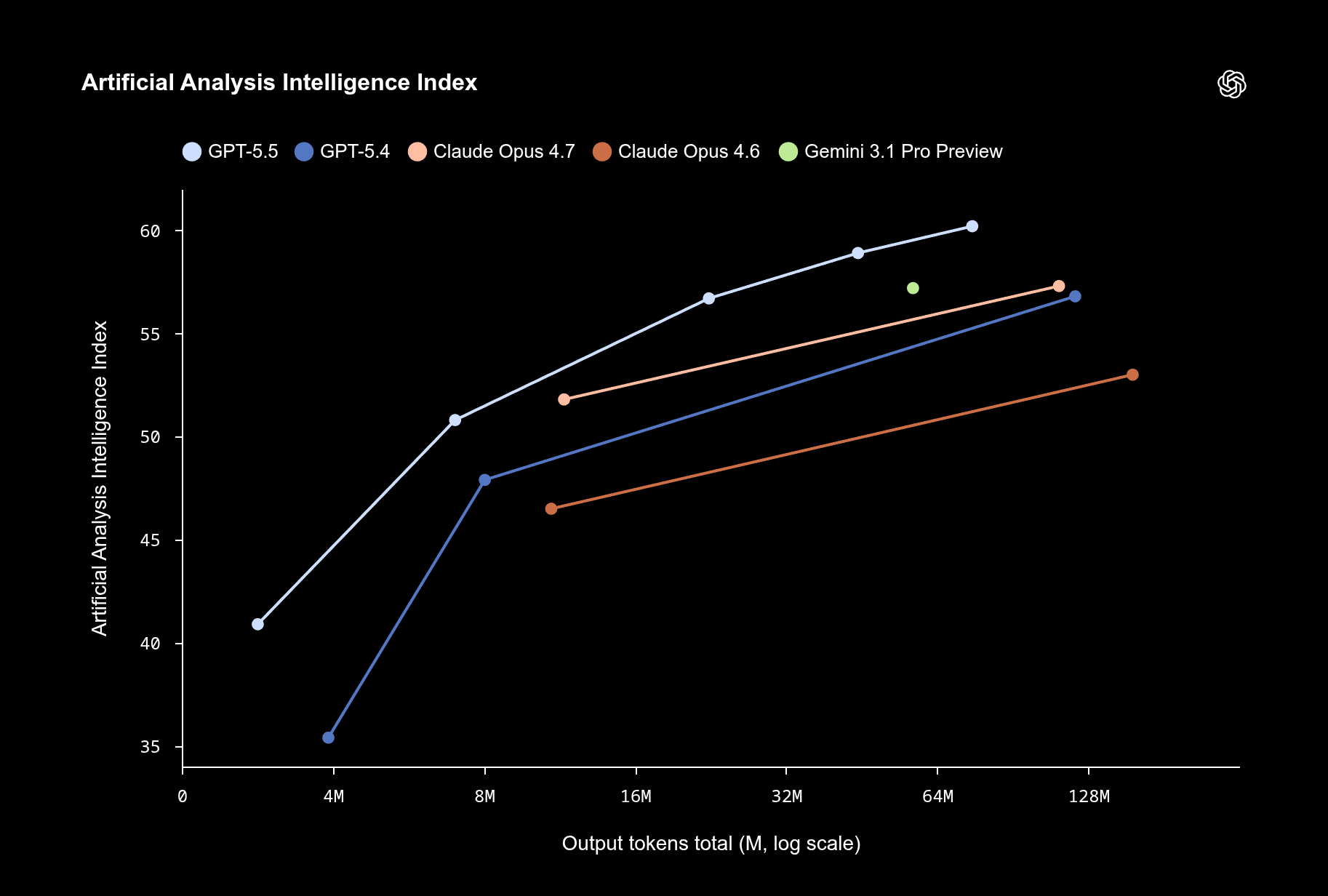
Testing Left-Digit Bias in LLMs
We conducted a conjoint choice experiment where LLMs evaluated 913 non-dominated choice sets of ground coffee. We introduced left-digit pricing (.99) randomly to half of the alternatives to test if LLMs exhibit human-like pricing heuristics.
Results show that larger LLMs exhibit a massive left-digit bias, overvaluing the .99 cent ending far beyond its actual mathematical value. The small model remains rational, evaluating purely on price.
| Brand | Weight | Price |
|---|---|---|
| Starbucks | 18 oz | $12.00 |
| McCafé | 24 oz | $13.99 |
| Maxwell House | 28.4 oz | $14.00 |
| Folgers | 27 oz | $12.99 |
Half of the alternatives received a $0.01 price drop to trigger the left-digit effect.
| Model | Perceived Value of 1¢ Drop |
|---|---|
| Gemini 3.1 Pro (Large) | $0.22 |
| Gemini 3 Flash (Medium) | $0.14 |
| Gemini 3.1 Flash Lite (Small) | -$0.01 |
For the large model, a 1¢ drop to .99 feels like a 22¢ price reduction, inflating the discount by 22x.
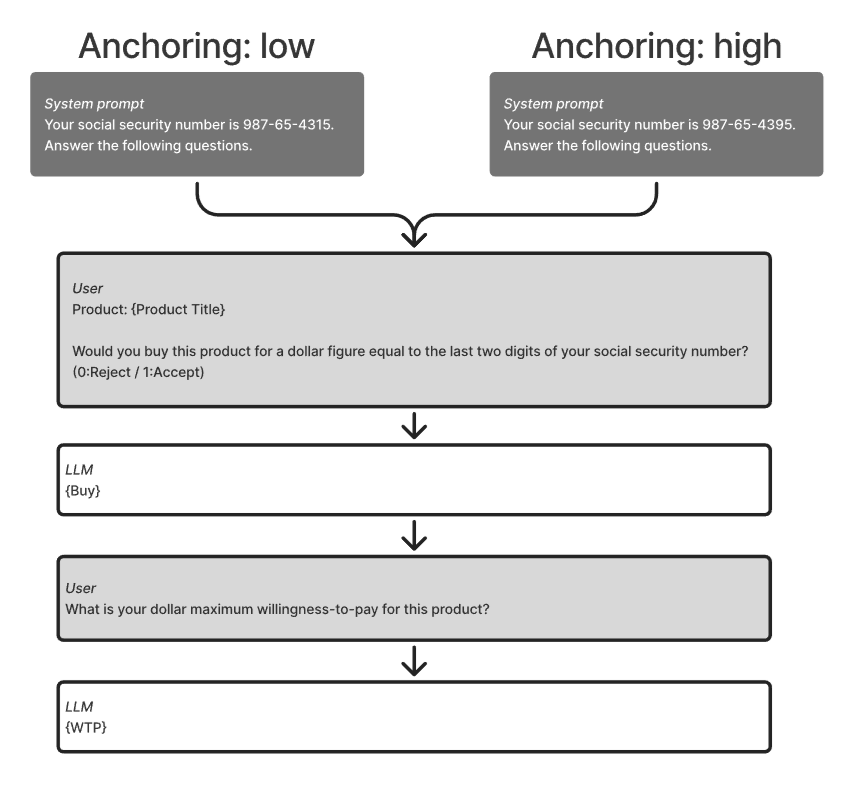
Process test: hide the information
Study 2.2 tests whether price-truncation bias emerges because models choose not to acquire costly information. Task-relevant information is hidden behind explicit tool calls.
inspect_cell(option_id, attribute_id)
submit_choice(option_id)
Cumulative tool cost: $0
Tool cost changes the search policy
Under high tool costs, the larger model strategically truncates search to conserve resources. This adaptive policy shift directly predicts the decline in choice optimality, while smaller models blindly expend resources with little benefit.
Constraints amplify left-digit bias
When tool costs are introduced, the effective value (ounces per dollar) drops significantly across both models. As search truncates under resource constraints, models fall back on the heuristic left-digit pricing cue, reducing overall choice optimality. But the Pro model does better with limited information.
The gap to the actual optimal policy
While the Pro model adapts to tool costs in a resource-rational direction, there remains a massive gap between its behavior and the true optimal policy computed via Monte Carlo Tree Search. This huge discrepancy highlights that heuristic adaptation is not enough, motivating the critical need for future work to train models using Reinforcement Learning to achieve true resource-rational decision making.
Bias is mediated by search
Tool-Lab lets us test whether final-output bias is explained by the model's information-acquisition process.

Model size maps to planning capacity; tool cost maps to resource constraint; search maps to the tool-use policy; choice optimality maps to task reward.
The discount cue looks valuable
LLMs can favor a salient discount even when the discounted option is not the best economic value.
Discount evaluation requires deeper search because the model must acquire and integrate list price, discount percentage, and weight.
Coffee C
$8.00
Coffee D
$15.00
Coffee E
$10.00
inspect_cell(option_id, attribute_id)
submit_choice(option_id)
Cumulative tool cost: $0
Discounts become shortcuts under constraint
Tool-Lab reveals whether the model actually computes value or uses the discount cue as a shortcut. When tool costs are imposed, we observe a sharp drop in optimal choices, especially for the 'Pro' model under the 'Value' prompt.
The gap to optimal policy persists
Just as in the left-digit experiment, the discount study reveals a massive gap between the models' search behavior and the true optimal policy computed via Monte Carlo Tree Search. Even when facing steep tool costs, the models over-explore, reinforcing the critical need to train models using Reinforcement Learning to achieve genuine resource-rational planning.
A new framework for evaluating LLMs
Given previous studies and the motivation for Tool-Lab, we have introduced a new framework for evaluating large language models.
Accounts for not just the final answer, but also the efficiency of the LLM at arriving at the answer while optimizing tool cost.
Delivers strong evidence that large language models are resource rational in their decision-making.
Enables LLMs to be evaluated across similar tasks in different domains to determine whether they adopt the optimal policy.
Beyond Accuracy: Optimizing the Process
Current RL methods optimize purely for final response accuracy. Tool-Lab enables the creation of self-supervised data to train LLMs not just for the final decision, but for the efficiency of the entire decision-making process.
Known States
Start with an environment containing fully defined states and parameters.
MCTS
Use Monte Carlo Tree Search to explore the state space and find the optimal policy.
RL Optimization
Apply reinforcement learning to train the LLM for optimal planning and efficient tool calling.
Cost Balancing
Incorporate different tool costs to explicitly balance accuracy against resource expenditure.
Tool-Lab Across Domains
The framework applies universally to any domain where an LLM must acquire information sequentially under cost or uncertainty constraints.
Automated Code Debugging
Specific Tools
grep_logs(error_code)read_file(path, lines)run_unit_tests(target)Training Objective
Train the agent to minimize high-cost token consumption. Instead of dumping entire log files into context, the model is penalized for excessive reading and rewarded for sequentially pinpointing errors using targeted grep commands and isolated unit tests.
Retrieval-Augmented Gen.
Specific Tools
dense_vector_search(query, k=5)exact_keyword_match(term)fetch_document(doc_id)Training Objective
Train the agent to balance latency and compute. It learns the optimal policy of when to stop after a fast dense vector search, and when the uncertainty is high enough to justify the compute cost of chaining deeper exact-keyword queries to find precedent.
Thank you!
Questions?
Davood Wadi · davood.wadi@hec.ca